我用 openai-edge-tts + n8n 搭了一个完全免费的本地文本转语音流程
在 Mac 上跑 openai-edge-tts,再用 n8n 的 HTTP Request 节点接入一个本地 TTS 服务,做出可自动化、可选音色、输出 mp3 的免费文本转语音方案。
今天折腾了一个我觉得挺实用的小系统:
在 Mac 上运行一个开源的本地 TTS 服务,再通过 n8n 调用它,把文本自动转成语音。
而且关键点是:
- 完全免费
- 本地可跑
- 可以接进自动化工作流
- 支持选择不同音色
- 最终可以直接输出 mp3
我用到的开源项目是:
openai-edge-tts
GitHub:https://github.com/travisvn/openai-edge-tts
这篇就记录一下我今天怎么把它跑起来,以及为什么我觉得这个方案很适合个人自动化使用。
为什么我想搞这个
文本转语音这件事,需求其实一直都在。
比如你会想把:
- 一段文字变成语音播报
- 一条通知自动读出来
- 工作流里的文本内容转成音频
- 某些文章或摘要快速生成可听版本
这些场景如果都走商业 TTS API,虽然省事,但长期用下来通常有几个问题:
- 要付费
- 有额度限制
- 依赖第三方服务
- 接自动化时不一定够灵活
所以我今天更想做的是一个:
够用、免费、可控,而且能直接接进自己工作流里的本地 TTS 方案。
我最后采用的方案
我最后用的是这套组合:
- 运行环境:Mac
- TTS 服务:
openai-edge-tts - 自动化编排:
n8n - 调用方式:
HTTP Request - 输出格式:
mp3
也就是说,整个流程可以理解成:
文本 → n8n → HTTP 请求本地 TTS 服务 → 返回语音文件
这类方案我很喜欢的一点在于,它不是单独一个 demo,而是能真正接进已有自动化流程里。
服务启动前,我先写了一个 .env
把项目从 GitHub 下载下来之后,我先在根目录写了一个 .env 文件,内容如下:
API_KEY=your_api_key_here
PORT=5050
DEFAULT_VOICE=en-US-AvaNeural
DEFAULT_RESPONSE_FORMAT=mp3
DEFAULT_SPEED=1.0
DEFAULT_LANGUAGE=en-US
REQUIRE_API_KEY=True
REMOVE_FILTER=False
EXPAND_API=True
DETAILED_ERROR_LOGGING=True这些配置大致是做什么的
API_KEY:本地服务的访问密钥PORT:服务监听端口,我这里设成了5050DEFAULT_VOICE:默认音色DEFAULT_RESPONSE_FORMAT:默认输出格式,这里是mp3DEFAULT_SPEED:默认语速DEFAULT_LANGUAGE:默认语言REQUIRE_API_KEY=True:要求调用时必须带 API KeyDETAILED_ERROR_LOGGING=True:调试时更方便排查问题
这一层配置很重要,因为它把整个本地服务的认证方式、默认音色、输出格式和端口都定下来了。
n8n 里我是怎么接的
我这边在 n8n 里用的是 HTTP Request 节点,直接去请求本地跑起来的 TTS 服务。
基本请求配置
- Method:
POST - URL:
http://host.docker.internal:5050/v1/audio/speech - Authentication:None
- Send Headers:开启
- Specify Headers:Using JSON
- Send Body:开启
- Body Content Type:JSON
- Specify Body:Using JSON
这里用 host.docker.internal,是因为我这边的 n8n 跑在容器里,需要通过这个地址访问宿主机上的本地服务。
Header 配置
我这里加了一个认证头:
Authorization: Bearer your_api_key_here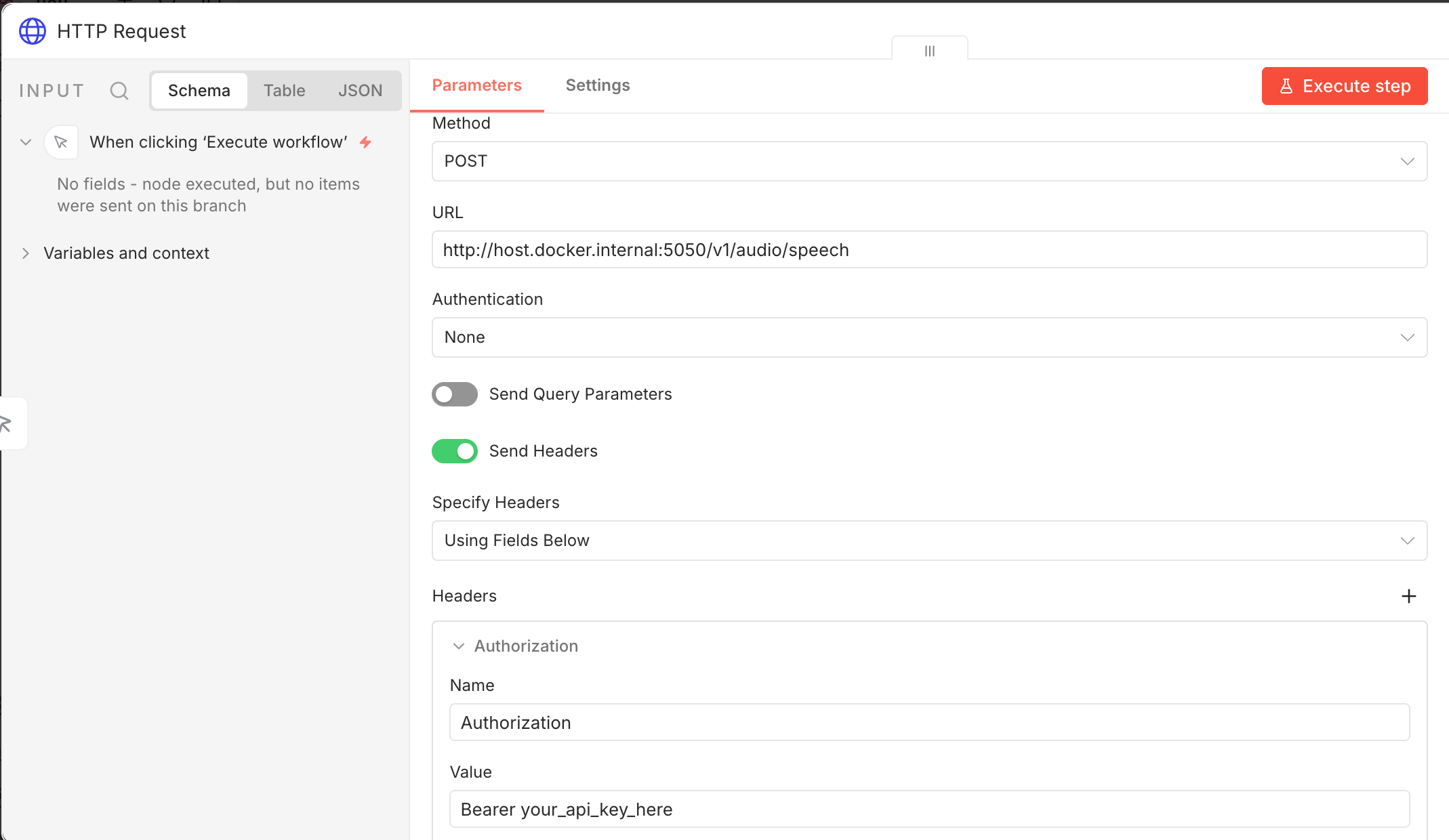
如果你的本地服务设置了 API Key,这一步就需要带上。
这里要特别注意:
.env里的API_KEY,和 n8n 请求头里的Authorization: Bearer ...,必须是同一个值。
比如你在 .env 里设置的是:
API_KEY=my_secret_tts_key_123那在 n8n 里就必须写成:
Authorization: Bearer my_secret_tts_key_123因为我这里开了:
REQUIRE_API_KEY=True如果这两边不一致,请求就不会通过。
Body 配置
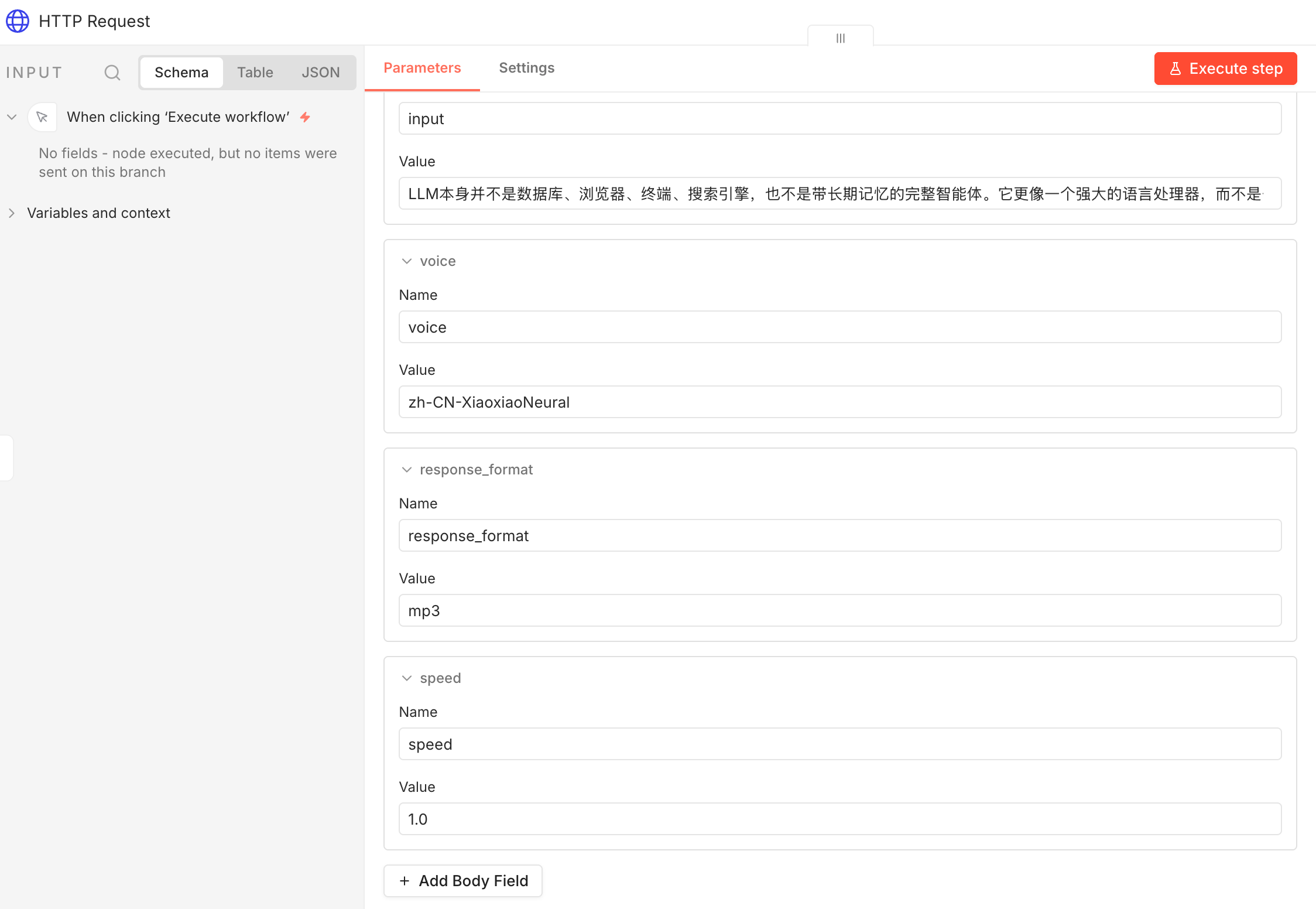
请求体里主要传这几个字段:
{
"input": "这里放要转语音的文本",
"voice": "zh-CN-XiaoxiaoNeural",
"response_format": "mp3",
"speed": 1.0
}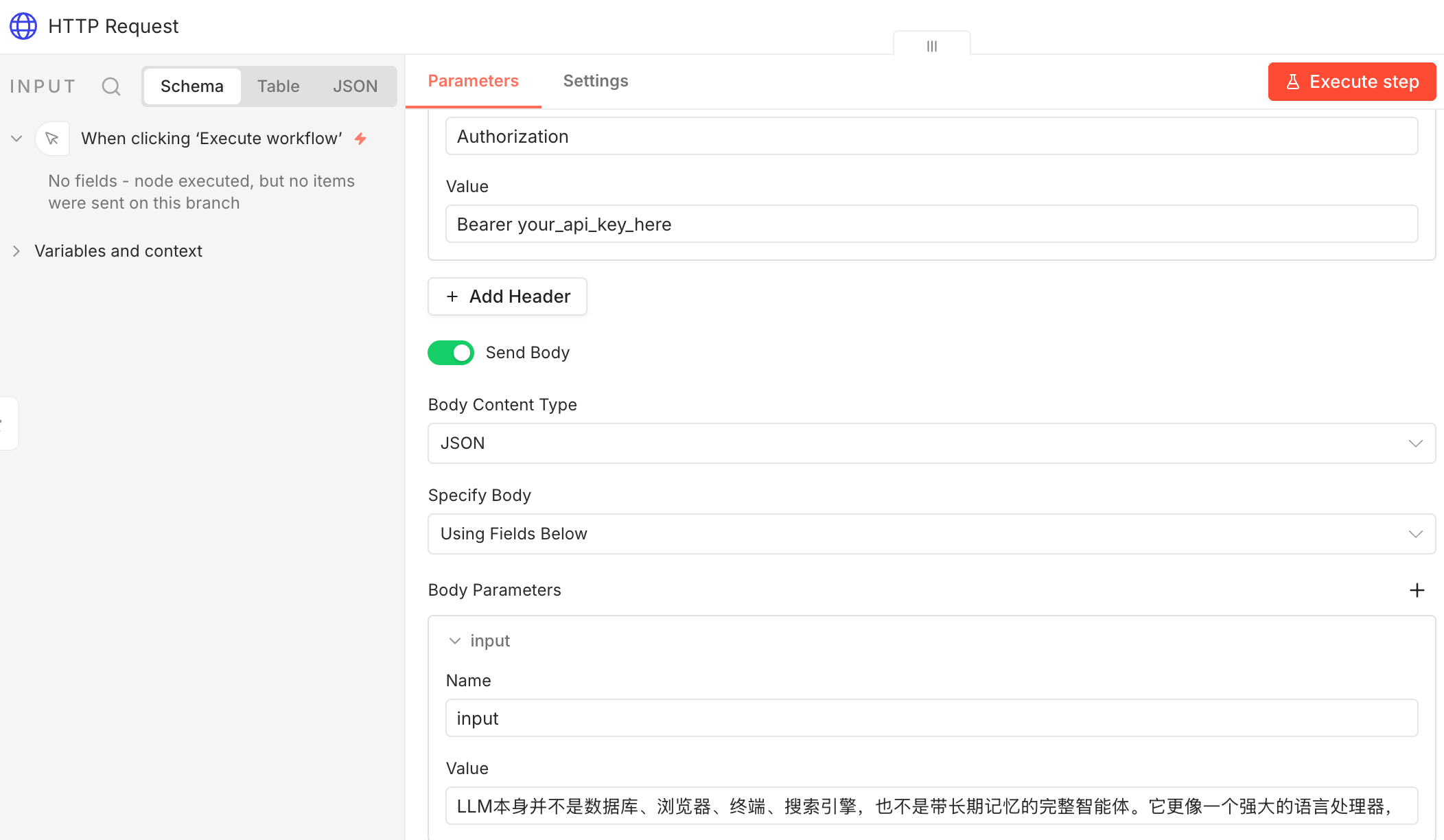
字段说明
input
要转换的文本内容。
voice
音色参数,对应你想使用的 voice 名称。
response_format
我这里直接设成 mp3,这样后面无论是保存、传输还是继续接流程都比较方便。
speed
控制语速,1.0 是默认值。
这一套为什么好用
一旦它被接成 n8n 里的 HTTP Request 节点,这个本地 TTS 服务就不只是“能跑起来”,而是变成了一个可以复用的能力节点。
后面无论你是要:
- 接 webhook 传来的文本
- 接 AI 生成的摘要
- 接通知内容
- 接文章或脚本片段
都可以统一走这一步,把文本输出成语音文件。
音色怎么选
这套方案还有一个挺实用的点:音色不是固定死的。
可以直接去这个页面试听和查看可用音色:
你在页面里选中喜欢的声音后,直接把对应的 voice 参数值填进 n8n 请求体就行。
例如一些常见中文音色包括:
zh-CN-XiaoxiaoNeuralzh-CN-XiaoyiNeuralzh-CN-YunjianNeuralzh-CN-YunxiNeuralzh-CN-YunxiaNeural
这就意味着你不仅能做“文本转语音”,还能根据场景切不同声音。
比如:
- 用偏自然的声音做摘要朗读
- 用更清晰的音色做通知播报
- 用不同 voice 区分不同工作流来源
对于自动化系统来说,这种可配置性其实很重要。
这个方案为什么值得
我觉得它最有价值的地方,不是“它能发声”,而是它在个人工作流里很顺手。
1. 免费
这是最直接的优点。
对于个人使用、实验和轻量自动化来说,免费意味着你可以更放心地接进流程里,不用每次都计算成本。
2. 本地可控
服务跑在自己的机器上,整个过程更可控,也更适合喜欢自己搭系统的人。
3. 很适合接 n8n
一旦它能被 HTTP Request 打通,就不再只是一个本地工具,而是一个可以嵌进自动化流程的组件。
这时候你就能做很多事:
- 新消息自动转语音
- 某段文本自动生成播报音频
- 博客摘要或日报自动语音化
- 某些提醒内容直接输出成可播放文件
4. 输出格式直接实用
直接返回 mp3,比只拿到一段临时数据更方便后续处理。
我觉得它适合什么场景
如果是个人项目或者轻量工作流,这方案很合适。
比如:
- 自动语音播报
- 内容摘要转语音
- 提醒系统
- 文章/笔记朗读
- 某些机器人或自动化助手的语音输出
尤其是当你已经在用 n8n 的时候,这种“能 HTTP 调用的本地能力”会非常自然地融进现有工作流。
它的局限也要说清楚
当然,这种方案也不是没有边界。
我目前的感受是:
1. 它更适合个人和实验型场景
如果你要做的是商业级、大规模、高稳定性的语音服务,那还是要评估更多因素。
2. 音色体验未必能完全替代成熟商用服务
虽然已经够用了,但如果你追求特别强的情绪表达、极高拟真度或者复杂语音产品能力,商用 TTS 依然有优势。
3. 本地部署意味着你要自己维护
这既是优点,也是代价。你获得了自由度,也要接受自己维护环境和流程。
我自己的一个判断
今天把这条链跑通之后,我更确信一件事:
对个人自动化来说,很多时候最重要的不是“最强”,而是“够用、免费、可控,还能接进自己的工作流”。
这类本地能力一旦通过 n8n 接起来,它的意义就不只是“一个开源项目能跑”,而是你多了一个真正可复用的工作流组件。
这也是我最近越来越喜欢的一类工具:
- 不一定最花哨
- 不一定最商业化
- 但能接得进系统
- 能长期自己掌控
最后
如果你也在找一个:
- 免费
- 本地运行
- 可自动化调用
- 支持选音色
- 能输出 mp3
的文本转语音方案,我觉得 openai-edge-tts + n8n 这条路很值得试。
至少对我今天这个需求来说,它已经不是一个“能跑的 demo”,而是一条真正可以放进日常工作流里的链路了。